Tabby食用指北
0x01前言
刚刚结束的安洵杯的ezjaba和之前长城杯的b4bycoffee都用到了tabby去寻找readObject->toString的链子。正好之前也想学tabby,这里就写一个搭建踩坑教程吧(指被折磨一天)
0x02环境配置
安装Tabby
地址: https://github.com/wh1t3p1g/tabby
Jdk版本: 最好选择8u292及以上(一些大师傅说的,我也没试过,我自己的版本是8u301)
进入GitHub项目地址会发现,Releases已经是老版本了,新版的并没有编译,需要我们下载项目之后自行编译。
进入下载好的项目文件夹,打开cmd,运行如下命令重新打包编译tabby
gradlew.bat tasks #查看gradle支持的命令
gradlew.bat clean #先clean,再打包,好习惯
gradlew.bat bootJar
运行完之后,编译好的tabby文件在/build/libs/路径下
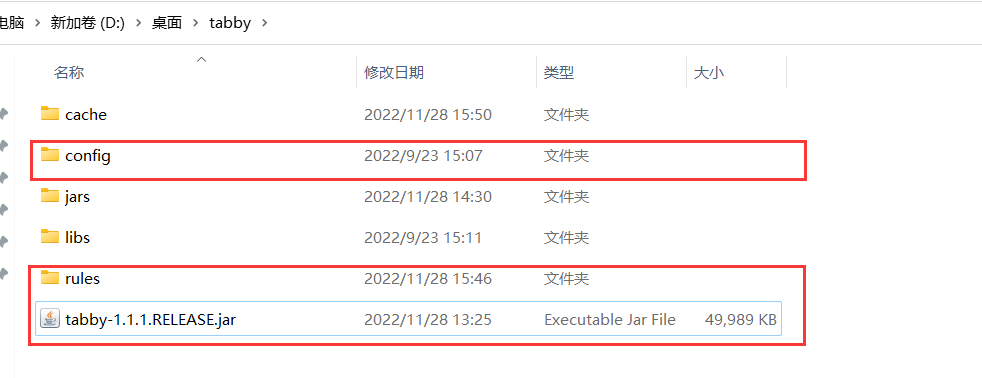
此时就可以新建一个tabby文件夹,让这个新tabby脱离项目了hhhhh,顺带把项目根路径的config和rules文件夹一起copy过来
然后去修改/config/settings.properties配置,以下是我的配置(仅供参考),然后创建两个文件夹jars和libs,前者用来存放要分析的jar包,后者用来存放你不想分析的依赖,但又会用到的。
tabby.build.enable = true
# jdk settings
# isJDKProcess 最好是true,不然会报soot的basic class的错误
tabby.build.isJDKProcess = true
tabby.build.withAllJDK = true
tabby.build.excludeJDK = false
tabby.build.isJDKOnly = false
# dealing fatjar
tabby.build.checkFatJar = true
# default pointed-to analysis 是否启用默认分析,如果是false则启用污点分析
tabby.build.isFullCallGraphCreate = false
# 扫描的Jar包目录路径
tabby.build.target = jars/
# 有些情况需要某些依赖,但是又不想分析这些依赖,此时可以放到lib目录下
tabby.build.libraries = libs/
# load to neo4j 是否开启图数据导入neo4j
tabby.load.enable = true
# debug 不知道有啥用,想开就开,我是开了的
tabby.debug.details = true
tabby.debug.inner.details = true
仅生成 jdk 的代码属性图
tabby.build.isJDKProcess = false
tabby.build.withAllJDK = false
tabby.build.excludeJDK = false
tabby.build.isJDKOnly = true
生成图时加入部分 jdk 依赖
tabby.build.isJDKProcess = true
tabby.build.withAllJDK = false
tabby.build.excludeJDK = false
tabby.build.isJDKOnly = false
默认加入3个基础 jdk 依赖,如需加入所有 jdk 依赖,则置 tabby.build.withAllJDK 为 true
生成图时选择特殊的 jdk 依赖
有些情况,我们并不想使用当前运行的 jdk 版本的依赖,而想直接分析特定版本的 jdk 依赖。
tabby.build.isJDKProcess = false
tabby.build.withAllJDK = false
tabby.build.excludeJDK = true
tabby.build.isJDKOnly = false
并且在 jars 目录放入指定要分析的 jdk 依赖即可。
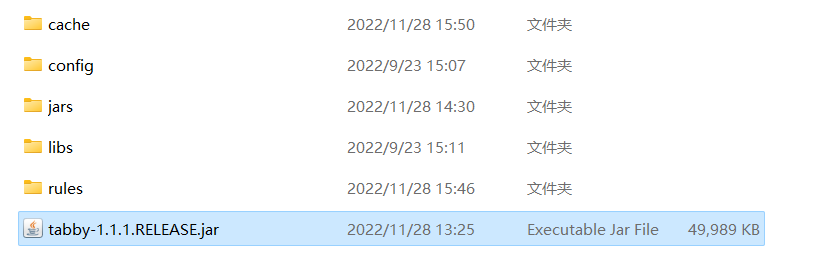
最终项目如下所示,其中cache是会自动生成的。
安装Neo4j
这里可以直接看wh1t3p1g师傅的指南1
安装tabby-path-finder插件
这里也可以直接看wh1t3p1g师傅的指南2,然后写一下我踩坑的地方。
运行mvn clean package -DskipTests命令打包编译的时候,需要使用Jdk11的环境,因为pom里写的Maven插件版本是11的,但我改成8又会爆新的错误,索性就直接用Jdk11去编译的了。我这里给一下我编译好的插件吧
https://wwt.lanzoue.com/iannM0h4lh3i
密码:7umf
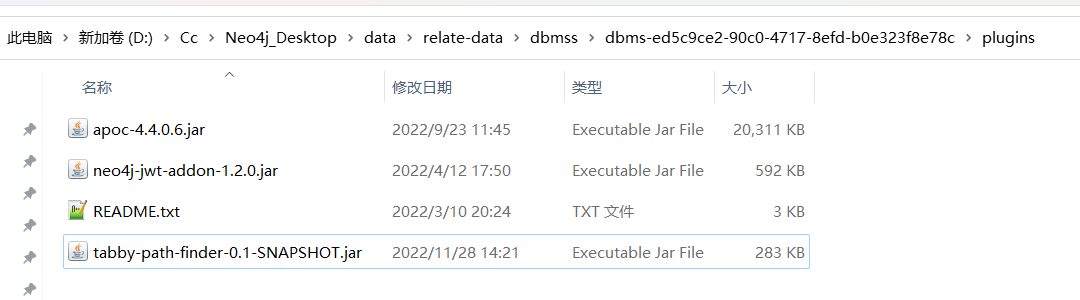
下载好之后就该安装了,相信看过上面Neo4j的配置,就知道怎么装插件了。这里直接把他丢到插件的目录下
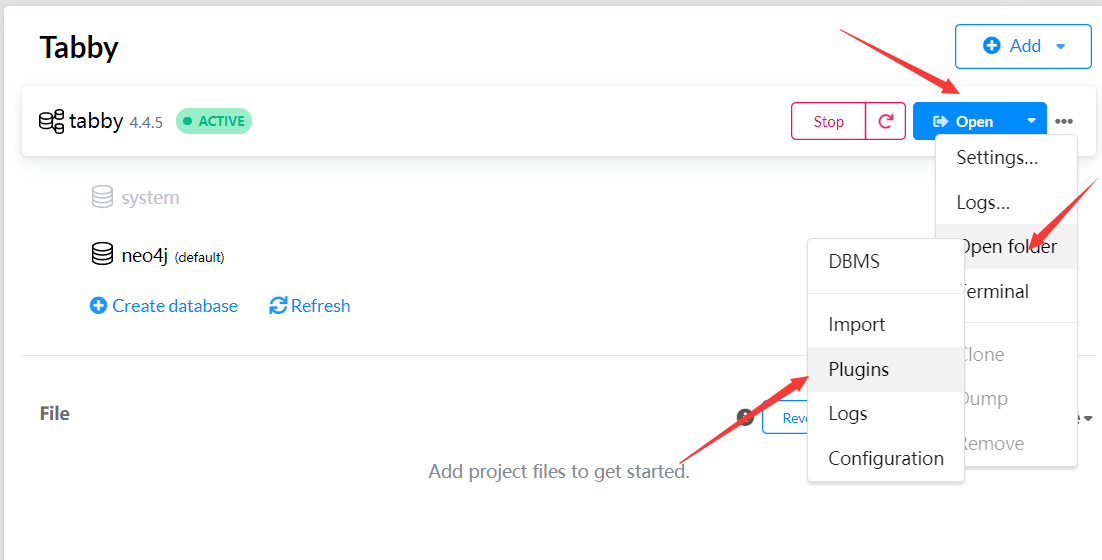
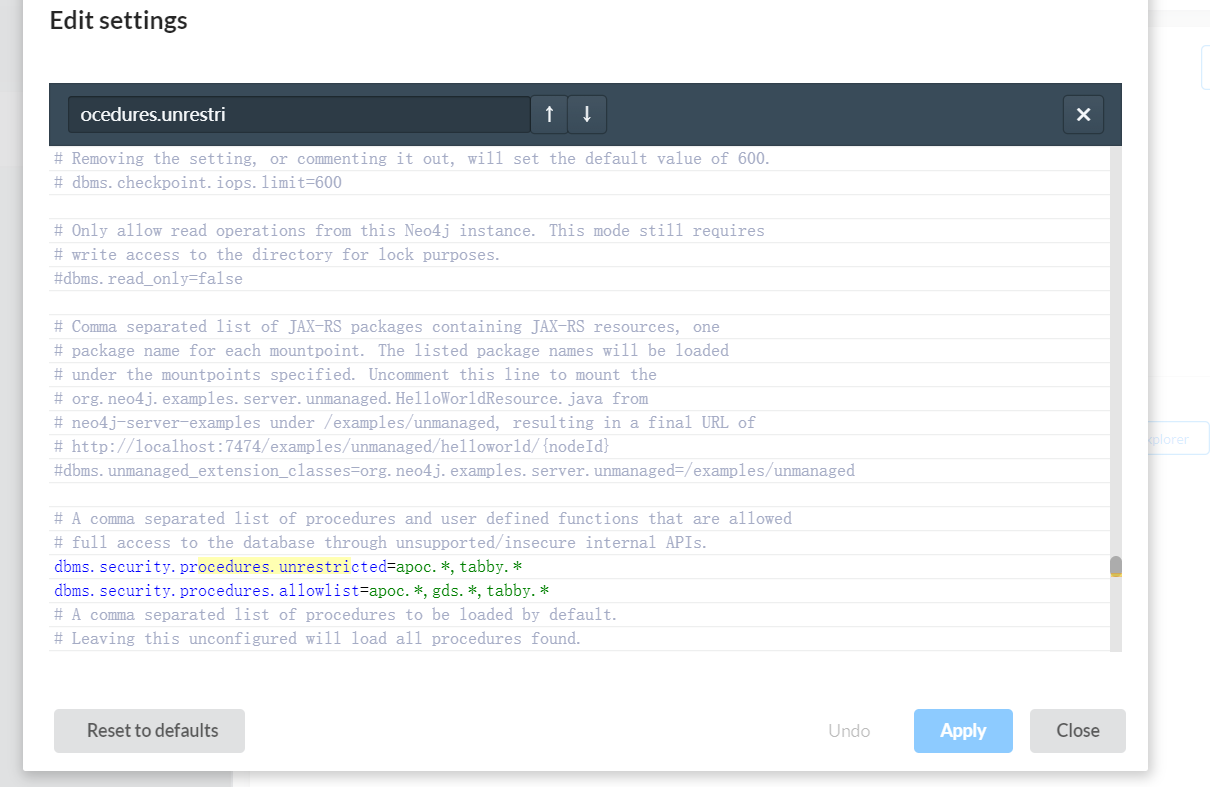
然后在配置中添加如下语句:
dbms.security.procedures.unrestricted=apoc.*,tabby.*
dbms.security.procedures.allowlist=apoc.*,gds.*,tabby.*
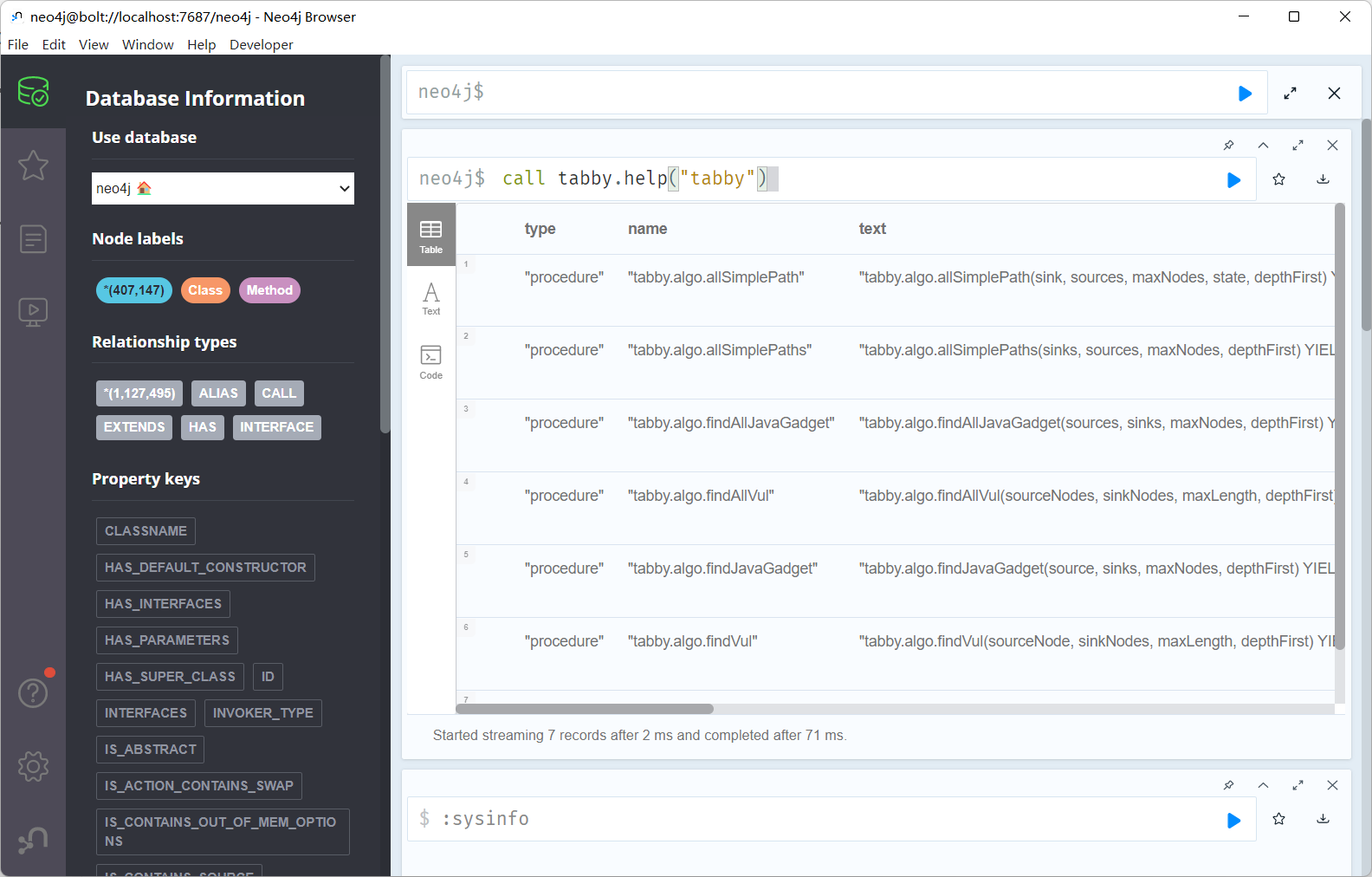
然后运行一下call tabby.help("tabby"),出现如下页面就是装好插件了
0x03使用方法
拿这个安洵杯为例,配置如下:
tabby.build.enable = true
# jdk settings
tabby.build.isJDKProcess = true
tabby.build.withAllJDK = true
tabby.build.excludeJDK = false
tabby.build.isJDKOnly = false
# dealing fatjar
tabby.build.checkFatJar = true
# default pointed-to analysis
tabby.build.isFullCallGraphCreate = false
# targets to analyse
#tabby.build.target = path/to/target
tabby.build.target = jars/
tabby.build.libraries = libs/
# load to neo4j
tabby.load.enable = true
# debug
tabby.debug.details = true
tabby.debug.inner.details = true
其中为了引入更多的类,就把Jdk全部丢来分析了: abby.build.withAllJDK= true
然后在jars目录里,把题目的jar包放进去。然后7zip打开题目的jar,把libs里的jar包丢进去
最后把Neo4j数据库跑起来,然后在Tabby进入CMD直接开Run!!!!!
java -Xmx8g -jar tabby-1.1.1.RELEASE.jar
大概要跑半个多小时,然后就可以进入Neo4j的浏览器里面开始查询了。
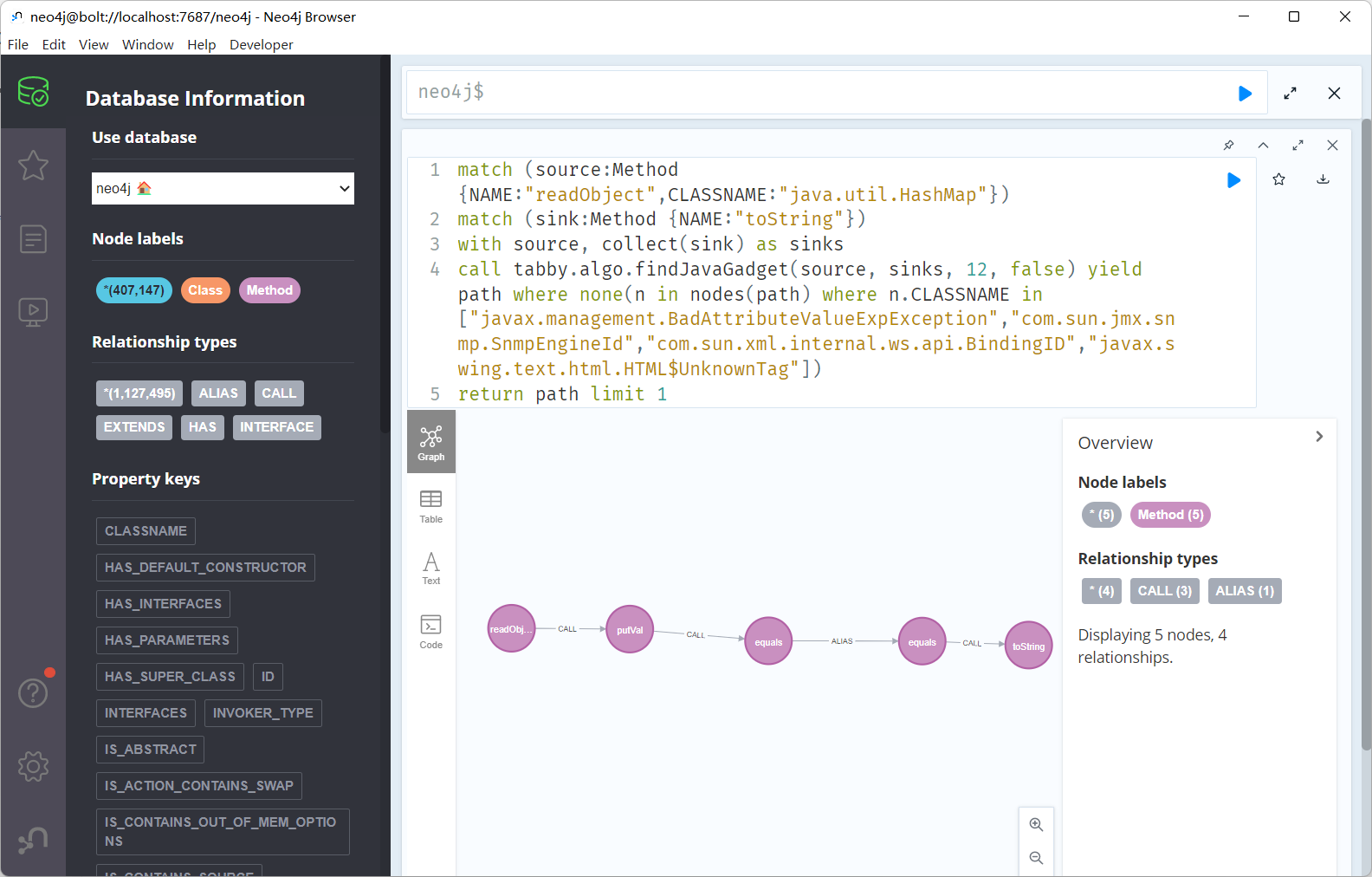
安洵杯这个题目需要寻找readObject->toString的链子
match (source:Method {NAME:"readObject",CLASSNAME:"java.util.HashMap"})
match (sink:Method {NAME:"toString"})
with source, collect(sink) as sinks
call tabby.algo.findJavaGadget(source, sinks, 12, false) yield path where none(n in nodes(path) where n.CLASSNAME in ["javax.management.BadAttributeValueExpException","com.sun.jmx.snmp.SnmpEngineId","com.sun.xml.internal.ws.api.BindingID","javax.swing.text.html.HTML$UnknownTag"])
return path limit 1
0x04踩坑后记
- 使用
tabby-path-finder插件的时候,一定得开启污点分析,也就是配置文件的abby.build.isFullCallGraphCreate = false必须是false,否则你会发现什么依赖都加进去了,也分析成功了,但查询返回结果为空...... - 再使用过一次之后,要想分析其他的jar包了,此时我们需要把
cache文件夹里的db文件删除掉,并且把rules/ignores.json文件也删掉。 - 初次使用差不多遇到的就这些...其余的坑就师傅们自己去踩吧~~~